
データマイニングとは?
概要や手法、活用事例をわかりやすく解説
データマイニングという言葉を見聞きするものの、データ分析など類似する用語との違いがよく分からないという方もいるのではないでしょうか。
この記事では、技術的な知識がなくても分かりやすいように、データマイニングの概要やどのように発展してきたかを歴史的な時間軸に沿って紹介します。また、データマイニングの分析手法や手順、活用例などについても解説します。
データマイニングとは、大量のデータを統計学的な手法などを用いて処理し、何らかの価値ある知識を得ることです。マイニング(mining)とは採掘を意味する英単語で、データの中から意味を見出すプロセスを、鉱山から鉱物を取り出すことに見立てて名付けられています。

データマイニングとデータ分析の違いとして、扱うデータの量や分析の進め方が挙げられます。データ分析では、データから読み取れることについて自分で仮説を立てた上で分析を進めるケースが一般的です。一方、データマイニングでは、大量のデータを対象として数理モデルなどを用いた解析手法で何らかの傾向や関連性などを見出します。
データマイニングの歴史は、企業にコンピューターが普及しはじめた1980年代から始まりました。1990年代になるとデータマイニングが広く認知され、専用ツールの開発や利用が進みます。2000年代以降、データマイニングをサービスとして提供するIT企業が増え、多くの企業がデータマイニングを活用するようになりました。
現在は、顧客の購買行動の分析や市場調査など、マーケティング分野でデータマイニングが注目されています。データマイニングで分析できるデータの種類は、数値やテキスト、画像など様々です。
近年、データマイニングが注目されている理由として、分析対象となるデータが増えていることが挙げられます。SNSの普及などによりインターネット上で取得できる情報量が増え、データマイニングの対象データを得やすくなったことが理由のひとつです。
機械学習などの分析技術が発展したことや、コンピューターの性能が向上し、高速な計算が可能になったことも、データマイニング分野への注目度を高めています。さらに、小売業や製造業、金融業など多くの分野の企業でデータマイニングを利用したマーケティング施策や経営の最適化事例が次々に登場していることも、注目が集まる理由のひとつです。

従来のデータマイニング手法では、一般的なデータ分析と同様に事前に仮説を立てた上で、分析結果の読み取りや仮説検証を行っていました。しかし、従来のやり方ではデータ分析に時間がかかることや、人間が立てた仮説の範囲内でしか知見を得られないことなどが課題でした。
しかし、このような従来のデータマイニングの課題は、機械学習の登場により解決されています。機械学習は、コンピューターにデータを入力し、一定のパターンやルールを学習させる手法です。大量のデータを自動的に分析できるようになったことで、データマイニングにかかる時間が短縮されました。また、人間が気付かなかったようなデータ内の関係性や特徴も、機械学習で読み取ることが可能です。
このように機械学習は、データマイニングと相性の良い技術のため、近年はデータマイニングに機械学習が用いられることが増えています。
機械学習について詳しくは機械学習とは?仕組みや活用例までわかりやすく解説をご覧ください。
データマイニングでデータを分析する仕組みには、複数の種類があります。主な分析手法は次の通りです。
クラスタリングとは、大量のデータを似ているもの同士でまとめ、クラスターと呼ばれるいくつかのグループに分ける分析手法です。
クラスタリングは、どのようなグループに分けるかを予め決めてデータを当てはめていく「分類」とは異なります。あくまでもデータの類似度を計算した結果をもとに、クラスターを作ることがクラスタリングの特徴です。
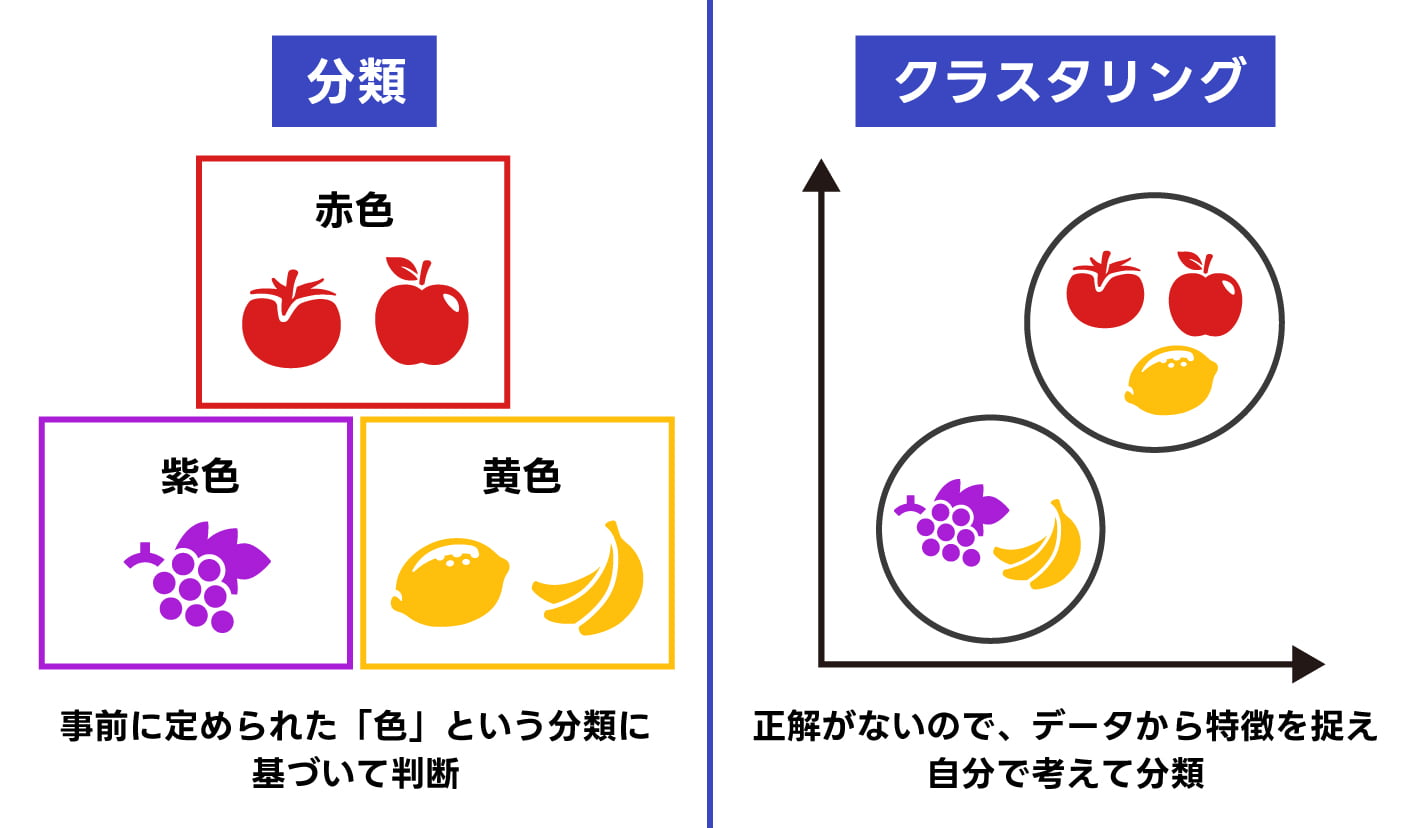
クラスタリングでデータ同士の類似度を計算する手法には、最短距離法や群平均法、ウォード法など様々な種類があります。いずれの計算方法を使う場合も、データの特徴が似ているもの同士をクラスターとしてまとめます。ただし、どのような特徴によってクラスター分けされたかは明示されないため、算出された結果を見て読み取る必要があります。
クラスタリングは、顧客の購買行動や属性に基づいて似た傾向の人をセグメントする(分ける)際などに効果的な手法です。あるセグメントに属する顧客が購入した商品を、同じセグメントの他の顧客におすすめするなど、マーケティング施策の最適化に活用できます。
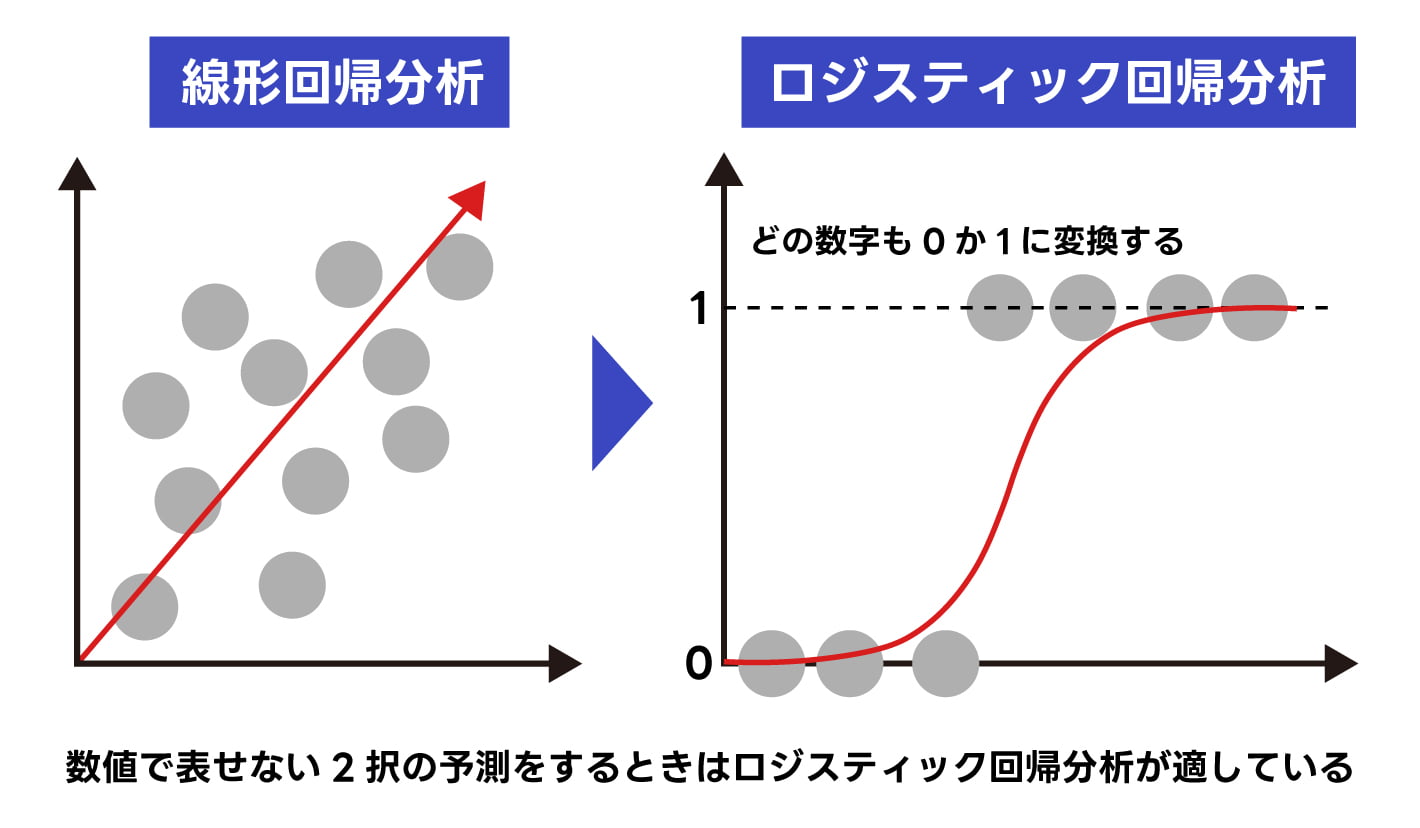
ロジスティック回帰分析とは、データが持ついくつかの要因をもとに、ある出来事が起きる確率を予測できる分析手法です。例えば、ある顧客の過去の購入回数や購入金額などのデータをもとに、今後特定の商品を買うか買わないかという二択の確率を求められます。
ロジスティック回帰分析と共通点の多い計算方法には様々な種類があり、それらの中でも線形回帰と呼ばれるものは分かりやすい例です。線形回帰では、データの特徴をグラフ上にプロットしていき、線形関係を導き出すことによって予測ができますが、買うか買わないかというような数値で表せない2択の予測をする際などにはロジスティック回帰分析が適しています。
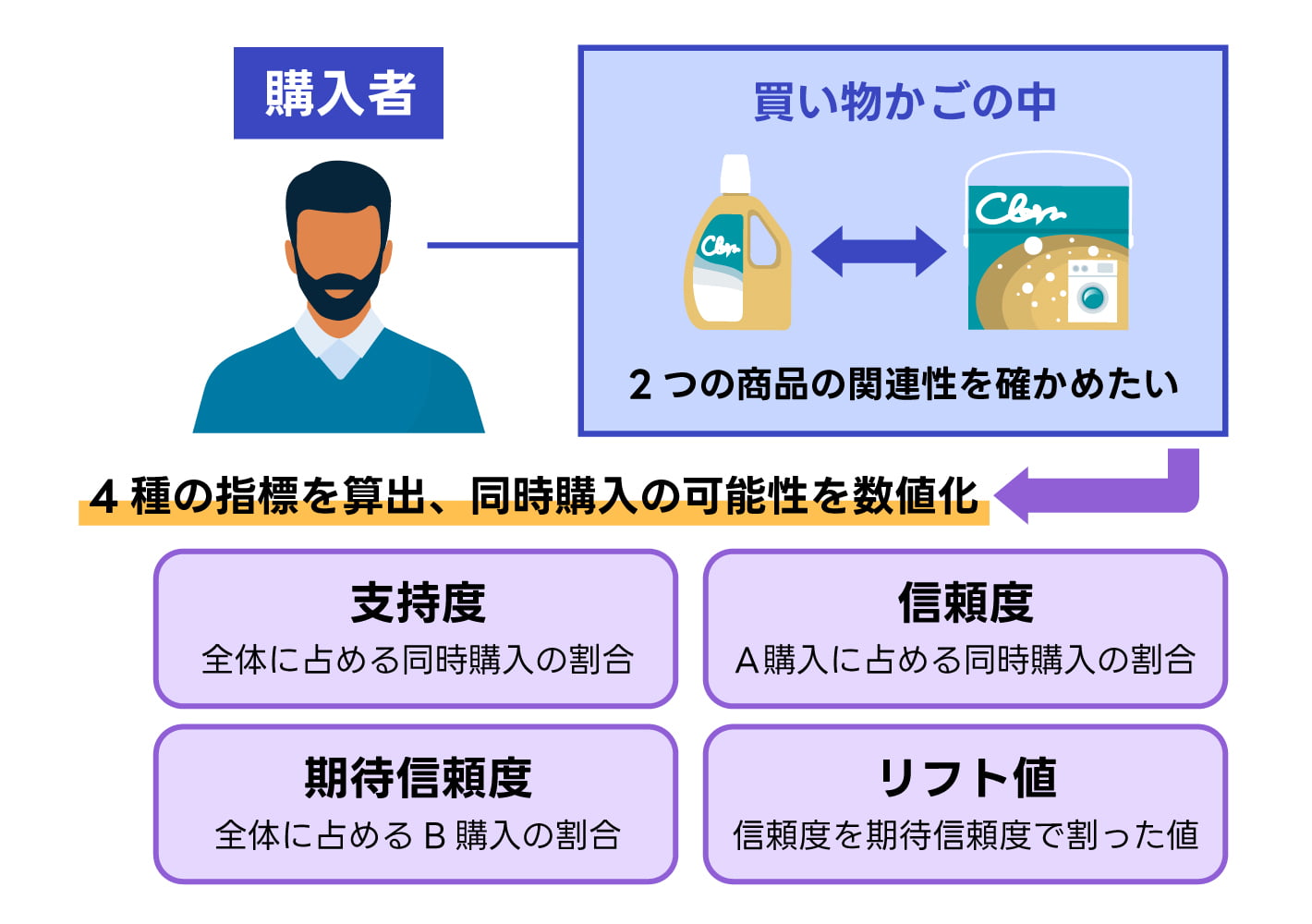
マーケット・バスケット分析は、データ間の関連性を分析する手法です。小売店やECサイトなどで、ある商品と一緒に購入されやすい商品が何かを分析する際に活用されます。
マーケット・バスケット分析では、関連性を確かめたい2つの商品の購入者数をもとに計算します。支持度や信頼度、期待信頼度、リフト値と呼ばれる4種類の指標を算出し同時に購入される可能性を数値化できます。
マーケット・バスケット分析の精度を高めるには、関連性を確かめる2つの商品の選び方が重要です。常に購入されている売れ筋商品を選んでしまうと、傾向が読み取りにくくなってしまいます。また、キャンペーンなどに売れ行きが左右されにくいタバコや、顧客属性を問わず購入されるミネラルウォーターなどの商品も除外して分析することがポイントです。これら以外の商品の中で、似たような属性の顧客が購入しそうなものを選び、マーケット・バスケット分析を行いましょう。
マーケット・バスケット分析は、ECサイトでおすすめ商品を表示するレコメンド機能にも応用されています。
決定木分析とは、YES・NOの2択でデータを分類したモデルを用いて分析を行う手法です。モデルの見た目が枝分かれした樹木のような形になることから、決定木分析と呼ばれます。
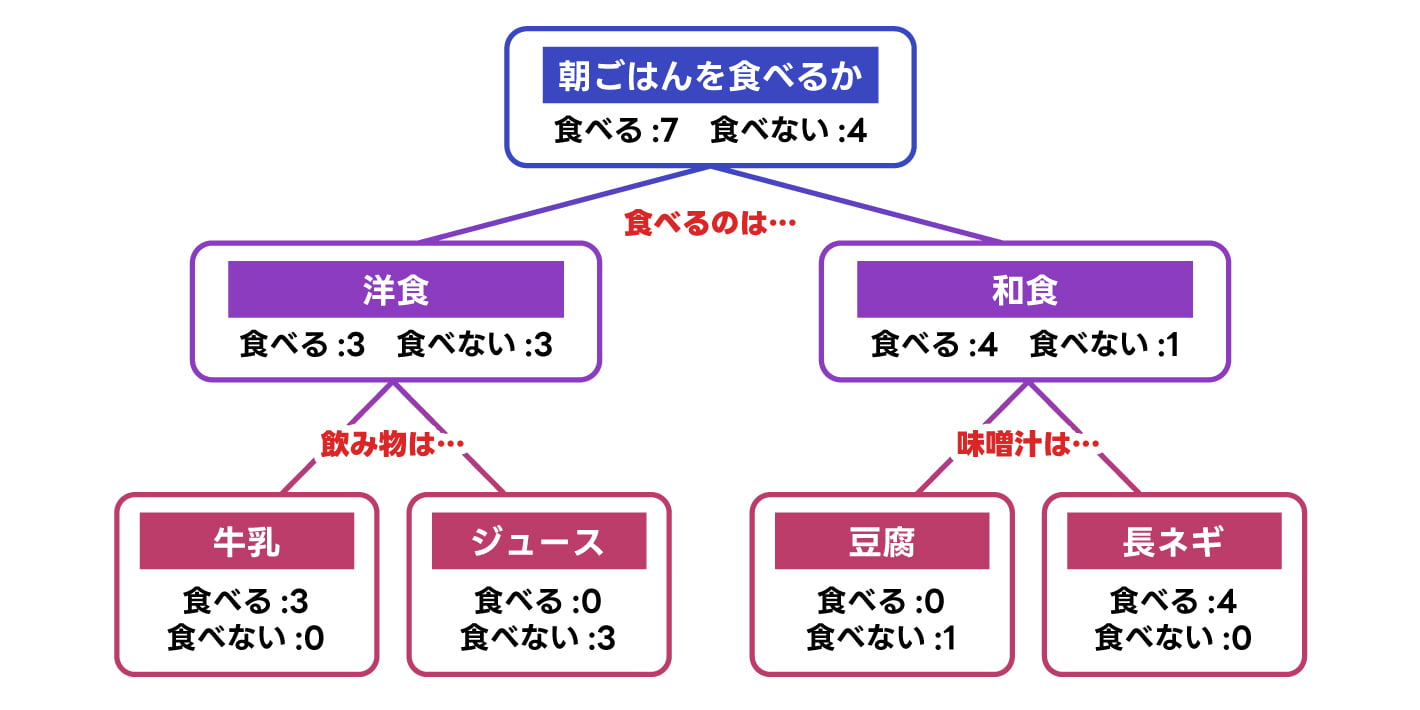
決定木分析を行うと、ある結果に対して影響を及ぼしている要因を導き出すことが可能です。例えばマーケティング分野では、ロイヤリティが高い顧客について、年齢層や企業を知ったきっかけ、初回に購入した商品の種類などどのような要因が大きな影響を与えているかを分析できます。
決定木を作る際は、どのような質問によってデータを分類していくかの設定が重要です。例えば、「年齢層は30歳以上かどうか」や「初回購入である商品Aを購入したかどうか」など、影響を与えている可能性が高そうな要因を想定して質問を決める必要があります。決定木分析に対応したデータマイニング向けツールなどを使用すると、決定木を効率的に作成することが可能です。
データマイニングを進めるプロセスは、使用する分析手法によって変わります。
ここではデータマイニングを行う一般的な方法を紹介します。

まずは、データマイニングを行う目的を明確化します。「顧客の行動データをもとにセグメント分けを行う」など、データマイニングによって得たい結果を具体的に決めましょう。
目的に沿ったデータを大量に集めます。すでに企業が保存しているデータのほかに、インターネット上に存在するデータなども分析の対象とすることが可能です。
分析対象のデータに不備があると、データマイニングを実行できません。値の欠損やデータ型の違いなどがあれば加工し、分析できる形にします。
データマイニングの処理を実行します。やり方が間違っていると正しい結果が得られないため、目的にあった分析手法を選ぶことが重要です。データマイニングツールによっては、目的やデータの内容に応じて推奨される分析手法を提案する機能が使える場合もあります。
出力された結果をもとに、要因の分析やセグメント分けなどを行います。
データマイニングをスムーズに実施するためのポイントは次の通りです。
計測・収集されたデータの中には、欠損やノイズのあるデータが含まれる可能性があります。不備のある生のデータは、データマイニングに使用することができません。データ品質を高めるために、分析の前段階でクレンジングと呼ばれる作業が必要です。

クレンジングを行わないと、不正確な分析結果が出力されたり、計算処理自体が正しく完了しなかったりします。データのクレンジングには多くの工数がかかるため、専用のソフトウェアなどを活用することがおすすめです。
データマイニングにおいては、正しい分析手法を選ぶ際などに専門知識が求められます。社内に統計に関するスキルを持ったスペシャリストがいない場合は、データマイニングツールの導入を検討しましょう。
データマイニングツールを活用すれば、手動でデータマイニングを行うよりも早く分析結果を得られます。また、複数の分析手法を手軽に試せることもデータマイニングツールを利用するメリットです。
クラスタリングや回帰分析をはじめ、様々な分析手法に対応したデータマイニングソフトやツールが存在します。ツールによって強みが異なるため、ツールを選定する前に分析の目的を決めておくことがおすすめです。クラウドサービスとして提供されるデータマイニングツールを利用する場合、個人情報など機密性の高いデータの取り扱いに注意しましょう。
データマイニングは、様々な業界の企業で活用されています。主な活用例は次の通りです。
顧客の行動データをもとに、詐欺や盗難などによる不正利用等を予測・検知するためにデータマイニングが活用されています。また、データマイニングによって保険加入者の支払額予測を立て、保険料を決めることも活用例のひとつです。
顧客の行動を予測したり、傾向を分析したりすることによるマーケティング施策の立案にデータマイニングが利用されます。また、季節や天候などの要因から商品の売れ行きを予測し、在庫管理を最適化することも可能です。
工場内の様々な機器の動きをセンサーやカメラを通じて画像データとして収集し、異常な動作を検知することにもデータマイニングが活用されています。製品品質やサプライチェーンの効率性などのリアルタイム分析も、データマイニングの活用例です。

生徒が受けたテストの採点データや活動履歴などを分析し、授業やテスト問題を一人ひとりにカスタマイズする際にデータマイニングが役立ちます。また、大学生の単位取得状況を分析し、留年するリスクが高い生徒をサポートするためにもデータマイニングが利用されています。
データマイニングは、大量のデータを様々な計算方法で処理し、有用な知見を得る手法です。ビジネスにおいては、顧客行動や売上などのデータを分析し、効果的なマーケティング施策を立案する際などにデータマイニングが活用されています。データマイニングを実行する際は、効率的に分析を進められるデータマイニングツールの導入がおすすめです。目的に合わせて、最適な手法でデータマイニングを行いましょう。

ITライター/新技術ウォッチャー。XR、ジェネレーティブAIなどの新しいテクノロジーや企業のDX取材、技術者・経営者へのインタビュー、技術解説記事などを執筆。ビジネスを軸にしたXRと最新テクノロジーのWEBマガジン『TechComm-R』運営。Yahoo!ニュース公式コメンテーター(ITジャンル)。株式会社ウレルブン代表。